2022-01-13 16:41:19
110
0
0
Learning a Probabilistic Latent Space of Object Shapes via 3D Generative-Adversarial Modeling

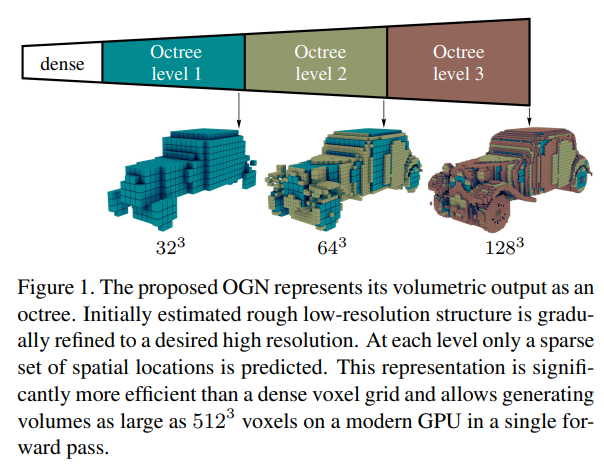
Octree Generating Networks: Efficient Convolutional Architectures for High-resolution 3D Outputs

Visual Object Networks: Image Generation with Disentangled 3D Representation

Improved Adversarial Systems for 3D Object Generation and Reconstruction

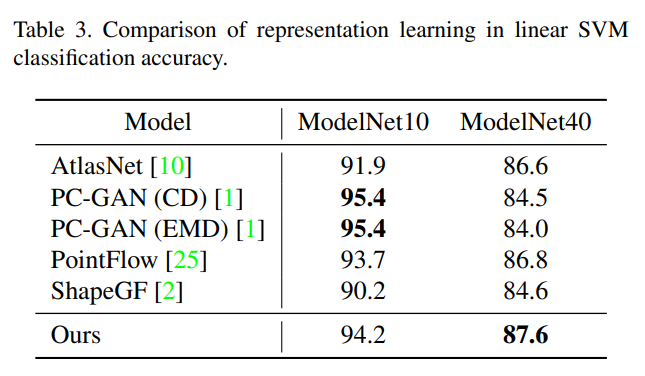
Learning Representations and Generative Models for 3D Point Clouds


PointFlow: 3D Point Cloud Generation with Continuous Normalizing Flows


Shape Inpainting using 3D Generative Adversarial Network and Recurrent Convolutional Networks


Learning Efficient Point Cloud Generation for Dense 3D Object Reconstruction


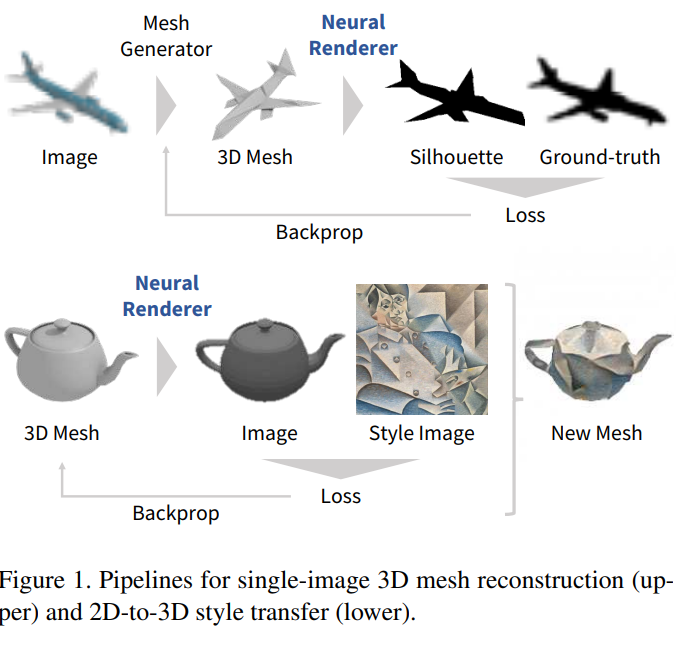
Neural 3D Mesh Renderer

SurfNet: Generating 3D shape surfaces using deep residual networks



BSP-Net: Generating Compact M
2021-11-27 22:54:12
157
1
0
- GRAF 为 Nerf 的生成形式变种,这里我们调研一下这种生成形式的隐式随机场的后续发展。
- 文章筛选条件: cite 了 GRAF (86篇),做的生成方向,训练数据为无监督数据集。
GRAF

π-GAN: Periodic Implicit Generative Adversarial Networks for 3D-Aware Image Synthesis (CVPR 2021 Oral)
- 把类似于 StyleGAN 的结构搬了进来
- 整体训练框架类似于 ProgressiveGAN,Discriminator 为 2D,分辨率逐渐增高,generator 只是采样密度逐渐增高。


video on github
video on zhihu
Generative Occupancy Fields for 3D Surface-Aware Image Synthesis (NeurIPS 2021)
- 看到了 open review, 四个7 才 poster???


预测一个累计密度而非体素密度,及累计密度>t则认为在物体内,否则在物体外,=t则为表面,以此改善 Pi-GAN 从而获得更精细的表面。
Unconstrained Scene Generation with Locally Conditioned Radiance Fields (ICCV 2021)
GNeRF: GAN-based Neural Radiance Field without Posed Camera
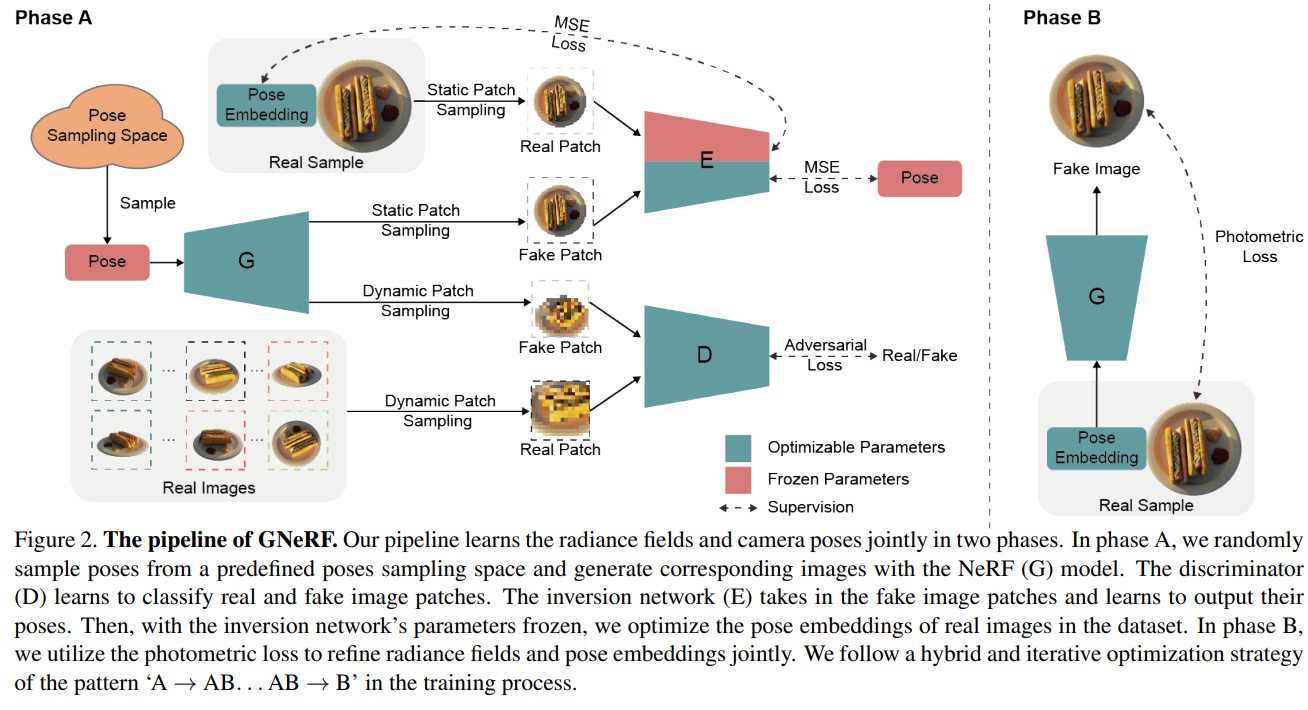
- 通过反复迭代估计出数据集里数据的pose.
CIPS-3D: A 3D-Aware Generator of GANs Based on Conditionally-Independent Pixe
2021-11-01 13:49:38
72
0
0
CORTICAL NEURAL PROSTHETICS (使用皮层信号控制假肢)
- 三个基本要素:chronic microelectrode arrays(微电极阵列,永久性植入用于持续性读取神经信号), extraction algorithms(读取算法), and prosthetic effectors(可控制的假肢)
- 基本公理: 在皮层神经元的放电模式相当直接地表示了对应的运动。
- 但是肌肉激活转化为肌肉力量本身是一个困难的非线性问题。人脑对于动作的编码是一组神经元组成的。实验表明可以通过重新编码皮层神经元群体的活动来准确预测手臂运动。
- chronic microelectrode arrays: 纯粹的植入性问题,显然马学长是专家。
- prosthetic effectors: 可控制的机械臂,似乎也不是我们研究领域。
- extraction algorithms: 神经信号解析及控制算法,这里可以做文章。
- 神经元对于信号的表示是取决于一段时间内的 fire rate。
- 一个神经元的单个轴突或者树突可能连接多个细胞。
- 目前前沿研究问题有:
- 植入后的设备会随时间失灵。(设备损毁或者细胞死亡或者神经元的tuning property)
- 人类运动控制也很依赖 feedback,所需还是需要和触觉形成闭环。
BCI
2021-10-18 10:35:29
178
0
0
Learning to Recover 3D Scene Shape from a Single Image

- 首次在单图像 3D 场景回复中考虑了焦距,从而显著提升了场景复原的效果。

- 网络分成两部分,一部分预测深度,一部分矫正深度+矫正焦距f。
NeuralRecon: Real-Time Coherent 3D Reconstruction From Monocular Video

- 使用 GRU 来完成了多帧之间的信息交流,而非以往的多个单帧做平均。

- 效果相对以往的方法似乎也没提升多少,但是速度快了不少。

#
2021-10-16 18:06:15
393
0
0
Diffusion Probabilistic Models for 3D Point Cloud Generation
- 把 Diffusion Probabilistic Models 做到了点云上。原来的加高斯噪音的操作变成了粒子的自由扩散操作。

- 效果上和其他模型似乎差不多
Convolutional Generation of Textured 3D Meshes
- 使用GAN 生成位移贴图(相当于球上每个顶点位移量, UV map 可以把球映射到平面)的方式来实现 3D mesh 生成。

Reconstructing Perceptive Images from Brain Activity by Shape-Semantic GAN
- 把 fMRI 得到的信息分为浅层和深层两部分,分别作
2021-10-15 16:42:04
373
0
0
任务分类

- 单人/多人 姿态估计, 2D/3D 关键点检测
- 2D多人关键点检测 top-down pipeline: 行人检测 -> 关键点检测
- bottm-up pipeline: 关键点检测 -> 关键点组装成人 (更快,但准确率更低)
- 发展路线 CPM,Hourglass -> OpenPose -> CPN -> MSPN -> HRNet
HRNet

- 多尺度分辨率融合
- 关键点两个主流的方法: 回归关键点位置, 估计关键点heatmap,然后将热图最大值的位置作为关键点。
- pipeline 几个部分
(1)stem: stride-2卷积降低分辨率。
(2)body: 生成与输入特征图分辨率相同的输出特征图。
(3)regressor(head): 估计K个heatmaps(表示关键点位置),然后映射到全分辨率上。
PoseAug: A Differentiable Pose Augmentation Framework for 3D Human Pose Estimation

- 将数据增强和模型训练关联起来,提出了一套可微的数据增强框架来生成训练数据,SOTA模型指标直接涨了9.1%
- 如何让生成的数据多样,且对模型训练是有益的: 将数据增强模块变成可学习的,根据训练传回的loss来调整数据增强的难度和内容
- 如何让生成的数据看上去自然,且真实合理: 用判别器来评估生成的数据的合理性,把反人类的动作给剔除掉
- 进行三个方面的变换:Bone角度(BA, Bone Angel)、Bone长度(BL, Bone Length)、旋转和变形(RT, Rotation and Translation)。
- 高斯噪声向量过MLP,变 (调节Bone角度,调节Bone长度,控制坐标旋转和变形)
- KCS: 关节点的坐标矩阵转换为一个Bone矩阵,矩阵的对角元素能表示每个Bone的长度,其他元素也可以表示Bone之间的夹角
- 本文在KCS的基础上,对不同关节进行拆分,分为五个组,即左右胳膊,左右腿,躯干,对每个组进行分别建立判别器,这样有助于维护生成姿态的多样性和合理性。
- 需要提前训练一个 2D 关键点估计的网络,然后本文注
2021-10-14 23:15:33
119
0
0
- CVPR, ICML, NIPS, ECCV, ICCV, AAAI, IJCAI 近一年的 best paper
2021-07-23 11:26:05
1189
0
0
all = ""$($(".input-metric-column-container")[3]).find(".job-table-row").each( function(){ ret = "[" $(this).find(".job-cell").each( function(){ ret += "'" + $($(this).find("p")[0]).text() + "'" + ", "; }); all += ret + '],\n';});console.log(all)
结果
all = ""$($(".input-metric-column-container")[5]).find(".job-table-row").each( function(){ ret = "[" $(this).find(".job-cell").each( function(){ ret += $($(this).find("p")[0]).text() + ", "; }); all += ret + '],\n';});console.log(all)
2021-07-06 10:17:20
1394
0
0
Imperceptible, Robust, and Targeted Adversarial Examples for Automatic Speech Recognition
- ICML 2019
- 根据听觉心理声学原理,让增加的adversarial 尽可能听不出来
- White-box,没有考虑时间偏移
Imperio: Robust Over-the-Air Adversarial Examples for Automatic Speech Recognition Systems
- 未发表
- white-box,没有考虑时间偏移
- 考虑了狭窄屋里回音(混响RIR)的问题(实际解决方案为把混响model成一个layer加在模型前面)
AdvPulse
- 发表于 CCS2020 (CCF 网络安全A类会议)
- 文章的创新点在于讨论了时间偏移,通过增加长度有限的一节 Universal Attack 来改变识别
- 通过将 adv attack 伪装成例如手机铃声来避免被人类发现
- 只做了 White-box Attack on
Speaker 识别, Speech 单词识别, Attack 是 Universal的(只与模型相关)
REAL-TIME, UNIVERSAL, AND ROBUST ADVERSARIAL ATTACKS AGAINST SPEAKER RECOGNITION SYSTEMS
- AdvPulse 同作者
- 无时间偏移考虑, Universal,white-box, 考虑 RIR
Devil’s Whisper
- 发表于 USENIX Security2020 (CCF 网络安全A类会议)
- 做了常见语音识别助手(如Cortana, Echo)的 black-box attack(传统老方法,一个模型逼近 black-box,然后 attack这个模型)。
- 没有考虑时间偏移
Audio Attacks and Defenses against AED Systems - A Practical Study
- 未发表
- 自称首个做音频识别的 Defense,cite了AdvPulse
- 发现超采样、A
2021-06-29 15:08:56
1470
0
0
- 使用的是 BigGAN 而不是 StyleGAN
- BigGAN 对于每一类物品使用的不是 One-hot + MLP,而实每个类别训练一个 embedding 向量,良好的解决了 imagenet 中有不同种类的狗、猫、鸟等问题。
- 初始时不是随机一个向量,而是初始随机了 N(about 400) 个初始位置,然后根据相似度(Discriminator后三层特征距离)选择最近的一个开始迭代。
- 用了 z22 作为 negative log likelyhood loss,来对 z 的分布进行正则化。
| dataset |
network |
params |
top1 err |
top5 err |
epoch(lr = 0.1) |
epoch(lr = 0.02) |
epoch(lr = 0.004) |
epoch(lr = 0.0008) |
total epoch |
| cifar100 |
mobilenet |
3.3M |
34.02 |
10.56 |
60 |
60 |
40 |
40 |
200 |
| cifar100 |
mobilenetv2 |
2.36M |
31.92 |
09.02 |
60 |
60 |
40 |
40 |
200 |
| cifar100 |
squeezenet |
0.78M |
30.59 |
8.36 |
60 |
60 |
40 |
40 |
200 |
| cifar100 |
shufflenet |
1.0M |
29.94 |
8.35 |
60 |
60 |
40 |
40 |
200 |
| cifar100 |
shufflenetv2 |
1.3M |
30.49 |
8.49 |
60 |
60 |
40 |
40 |
200 |
| cifar100 |
vgg11_bn |
28.5M |
31.36 |
 wuvin
wuvin