2022-10-31 17:07:19
195
0
0
图像生成
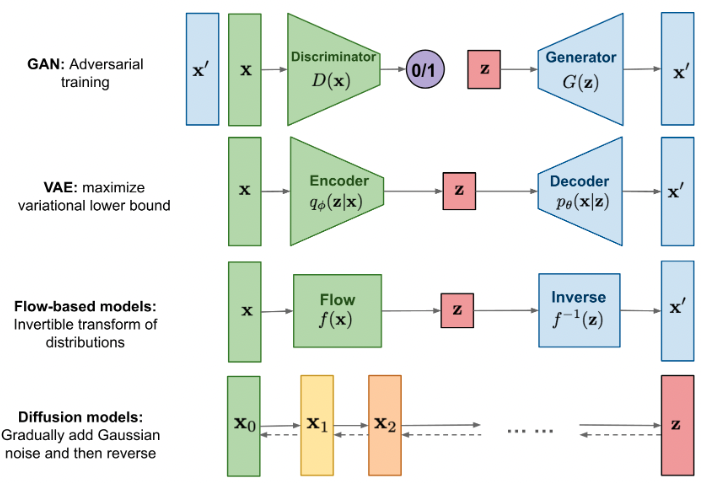
- 本质上是给出一个数据集X,然后用一个生成模型去估计这个分布 p(X)。估计方法有 Autoregressive models, Normalizing flows, Energy-based models, GANs, Diffusion models.
- 2022年之前,主流也是质量最高的方法是用 GAN。GAN包含一个生成器,即一个 N(0,I)→p(X) 的模型,和一个判别器 X→a。生成器从噪音中通过一遍神经网络推理得到所生成的图像。判别器输入一张真实/生成的图像,然后判别是否为真实图像。训练时,生成器和判别器是轮流迭代的对抗学习过程。期望情况下,最终生成器能够完美的从噪音生成正确的原始图像的分布,而判别器则刚好无法判别真伪。最常用的开源代码是Nvidia 公布的 StyleGANv2,github拥有超过1万个stars。
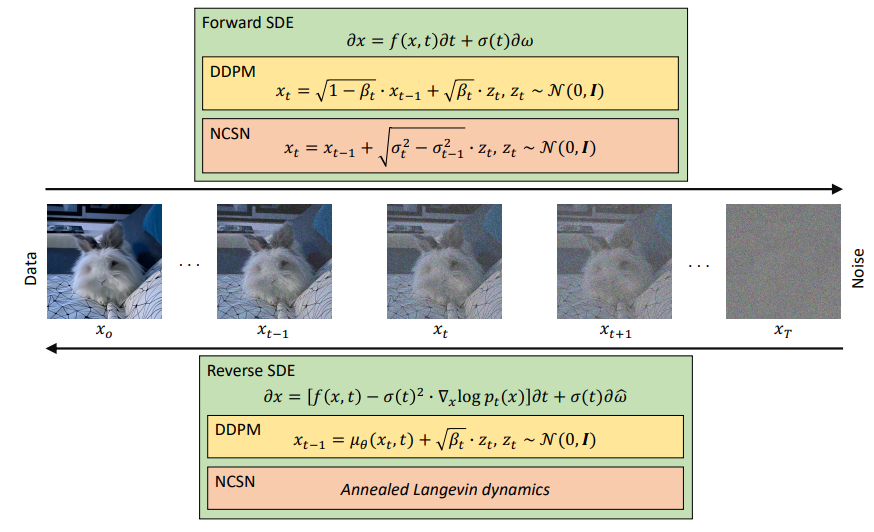
- 但是GAN拥有一个天生的缺点——基于对抗迭代的训练方法并不稳定。近两年来,Diffusion models 快速崛起,Diffusion models也是从噪音中生成一张图像,但方法不同。简单而言(因为其实有其他更复杂的分支方法),就是训练一个去噪的神经网络,通过对图像反复去噪,最终达到生成图像的效果。训练时,只需要正向给图像添加噪声,然后就获得了用于训练去噪网络的图像数据对。目前最火爆的开源代码是 latent-diffusion,拥有4.8K stars。
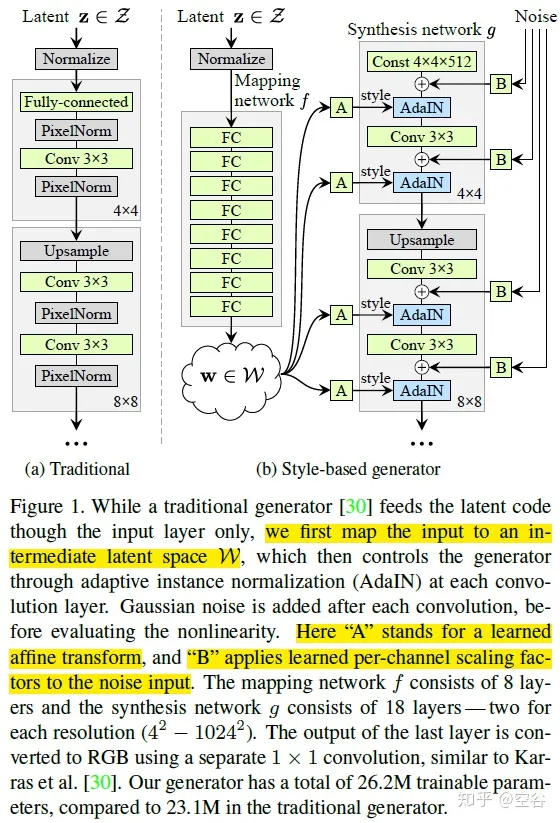
StyleGANv1
- 最早版本的 StyleGAN 研究如何实现可控风格化,引入了 mapping network 把一个高斯分布映射到控制信息 w的分布,然后再在生成过程中逐层加入控制信息w来实现可控生成。
2022-10-13 16:44:02
230
0
0
Introduction
- 此处跳过对 DALLE 的VAE模型的回顾。
- 此处跳过对 CLIP 的回顾。
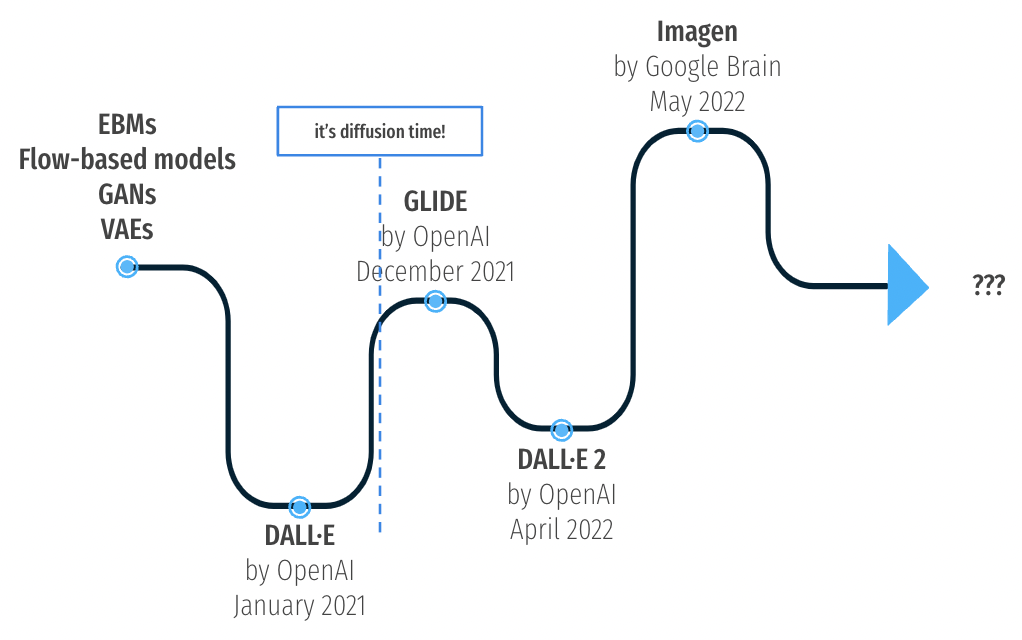
All you need is diffusion
- 去噪模型是受热力学启发而来的,如下我们开始讲述去噪过程
2022-09-13 18:25:39
476
0
0
显式
- Depth Synthesis and Local Warps for Plausible Image-based Navigation(13 年的文章):先根据多视角图生成相机视角和点云,然后把场景投影到点云并建立super pixel,查询的时候找出最近的四个视角,然后使用加权的局部保持形状变换得到结果。
- Scalable Inside-Out Image-Based Rendering(16年):RGB-D数据建立基于面片的场景重建。
- Photo tourism: exploring photo collections in 3D(06年):应该是最早的了,每张图片映射到一个空间上的平面,然后新视角根据看得到的部分合成。
- Modeling and rendering architecture from photographs: A hybrid geometry- and image-based approach(1996):从多张图片中重建基础几何结构,然后再在第二部进一步改进第一步得到的几何结构细节。
- AtlasNet: A Papier-Mach Approach to Learning 3D Surface Generation(2018): 从point cloud/RGB-image 到表面点云, 从表面点云到mesh
- Surface light fields for 3d photography(2000): 引入了表面Mesh上某个顶点在不同视角下颜色不同的概念(使用一个正多面球体刻画)。
离散体积
- A theory of shape by space carving(2000):从一系列环面视角完成场景重构以及 NovelView 合成的传统算法,考虑了可见性。
- Soft 3d reconstruction for view synthesis(2017):输入图片->带Voxeld 深度图->分析前后遮挡关系->计算了遮挡关系的深度图体积分布->合成。非NN算法。
- Photorealistic scene reconstruction by voxel coloring(1
2022-08-24 11:00:39
118
0
0
NeRF for Outdoor Scene Relighting(ECCV2022)
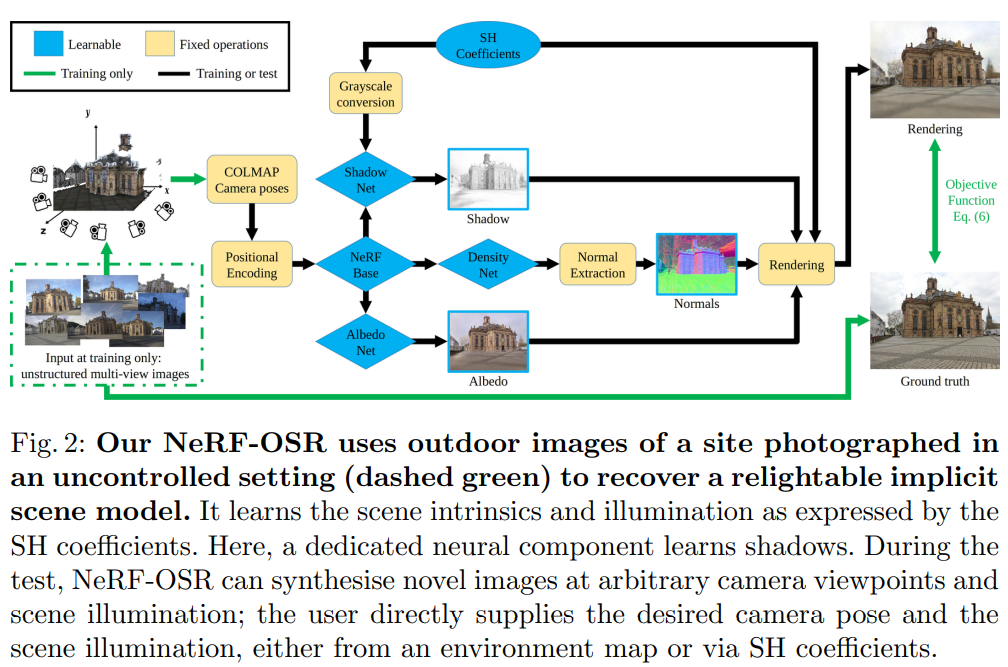
- 首个尝试解决室外复杂光照条件 relightning 的文章。
- 还顺带造了个数据集,通过色卡校准 Albedo 场景。

- 比别的方法高 1PSNR。
NeRV(CVPR2021)

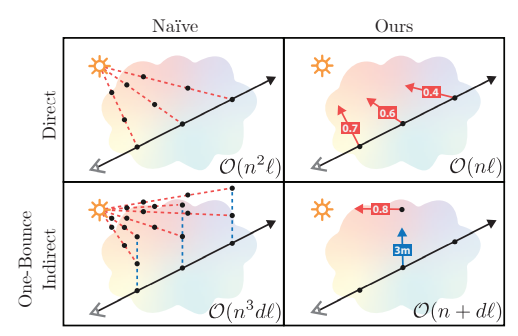
已知光源,简单场景,添加初步光追逻辑。
NeRFactor
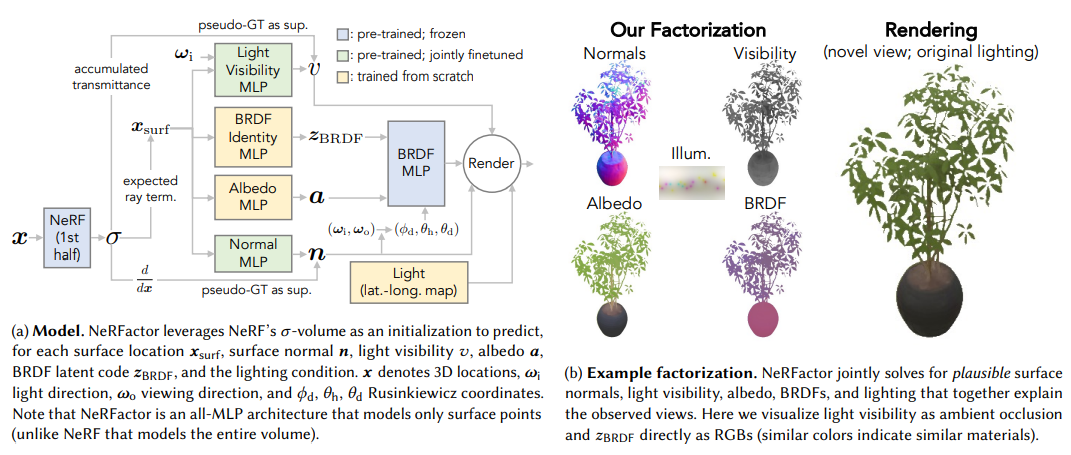
未知光源,简单场景,预测光源可见性。
NeRD (ICCV2021)
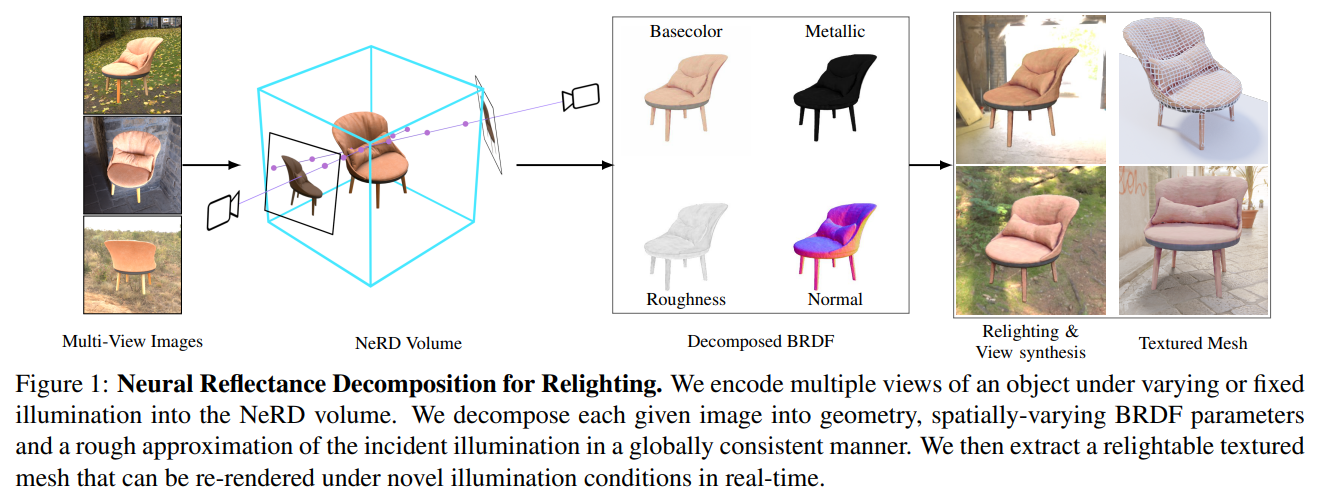
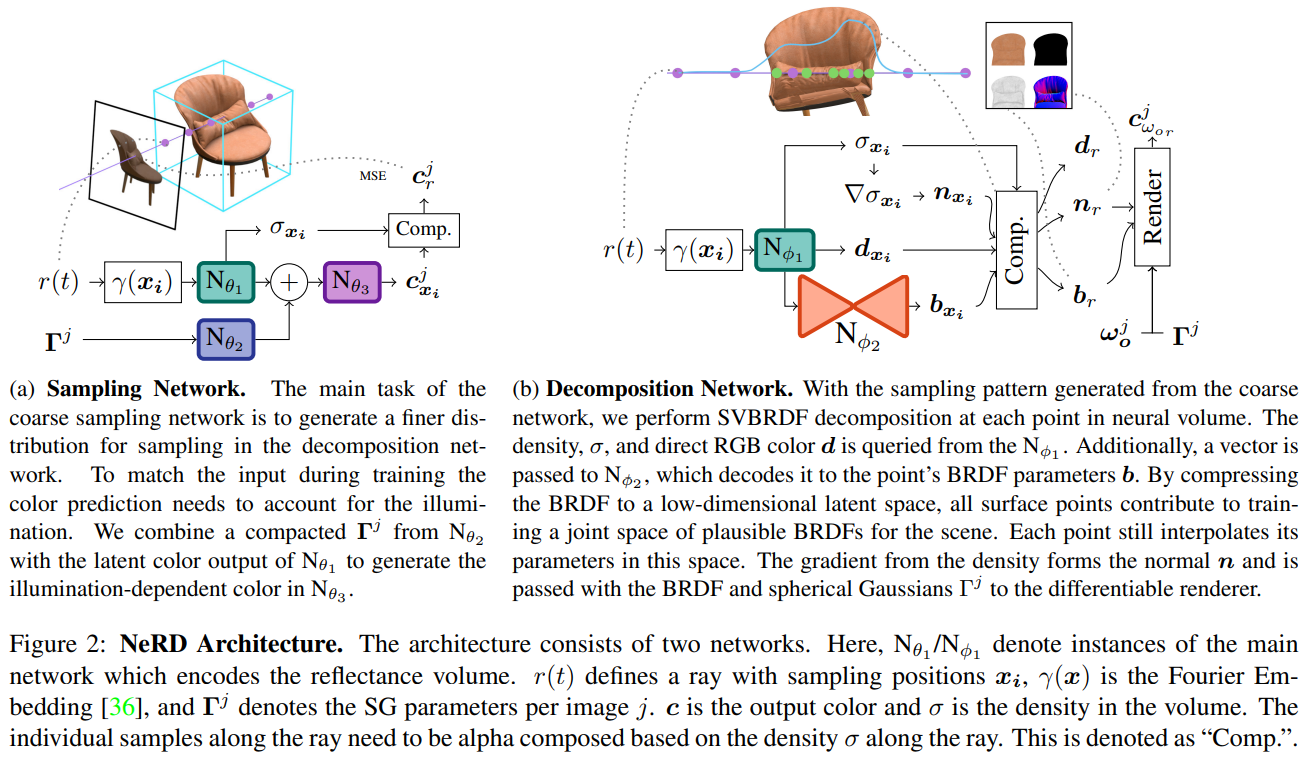
2022-07-17 20:59:53
213
0
0
NeuroFluid: Fluid Dynamics Grounding with Particle-Driven Neural Radiance Fields
- NeRF + 物理,根据观察到的流体现象,推测对应的粒子系统运动,并且预测之后的运动。
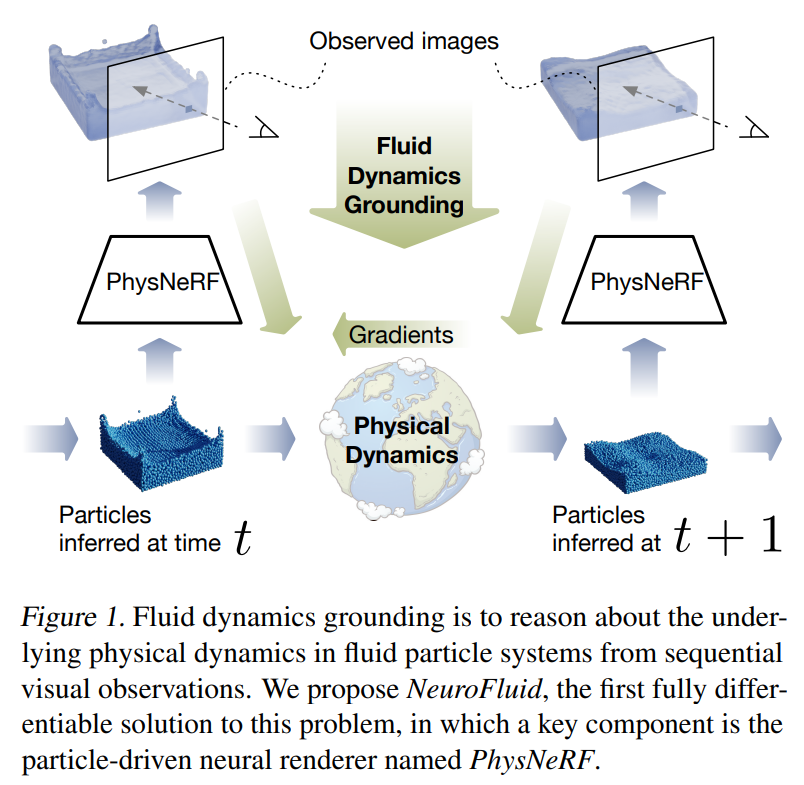

2022-07-11 15:23:01
720
0
0
Point-NeRF: Point-based Neural Radiance Fields (CVPR 2022 Oral)
- 竟然拿了 Oral,那么之前提的凭借版改进优先级又高了一些。
NeRF in the Dark: High Dynamic Range View Synthesis from
2022-05-19 10:34:39
111
0
0
The relativistic discriminator: a key element missing from standard GAN
- 不再判断一个样本的绝对真假性,而是判断相对真假性。
- 经过一系列论证和推到,操作非常简单,也就是过sigmoid转概率前相减。
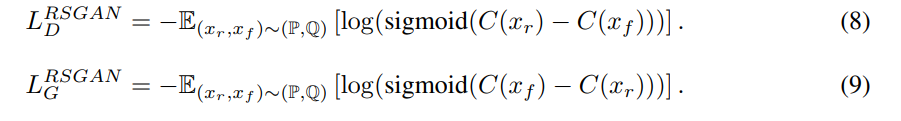
- 文章后面的实验也证实了这个简单的修改效果确实好
- 但是在github issue 中有人发现这样修改后,容易出现 model collaspe.
2022-05-02 16:07:11
168
0
0
Which Training Methods for GANs do actually Converge?
- 一篇理论性的文章,结果没有多么惊艳。但今后写某些文章的时候可能可以用于作为理论依据。

Optimizing the Latent Space of Generat
2022-04-28 16:23:12
130
0
0
- 本次以点云和体素生成为主,目的是调研下到底多大的算力能支持多复杂的场景。
Learning Representations and Generative Models for 3D Point Clouds (2018)
- 重建部分为 AutoEncoder,生成部分结构为常见GAN或者在AE的hidden space 上做GAN or 高斯混合模型。输入输出维度为 2048*3。GAN的深度只有一两层MLP。使用的数据集大小大约为 1.4GB,57K 个样本,代码中GAN的训练使用了268K iteration。
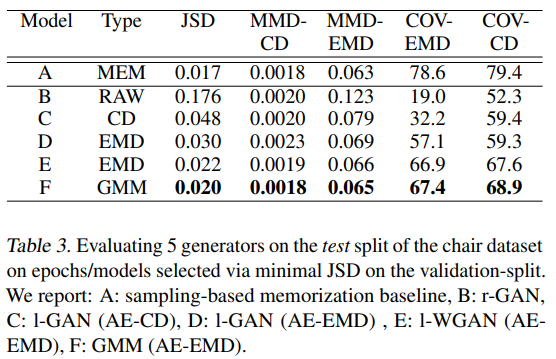
- 重建质量

- 不同方法的结果(竖着的是不同的测评方法;B是直接GAN;CD是在AE的hidden space 做GAN,AE使用了不同的损失函数Earth Mover's Distance 和Chamfer Distance;E是WGAN;F是Gaussian Mixture Model):
Improved Adversarial Systems for 3D Object Generation and Reconstruction (2018)
- 算法结构:
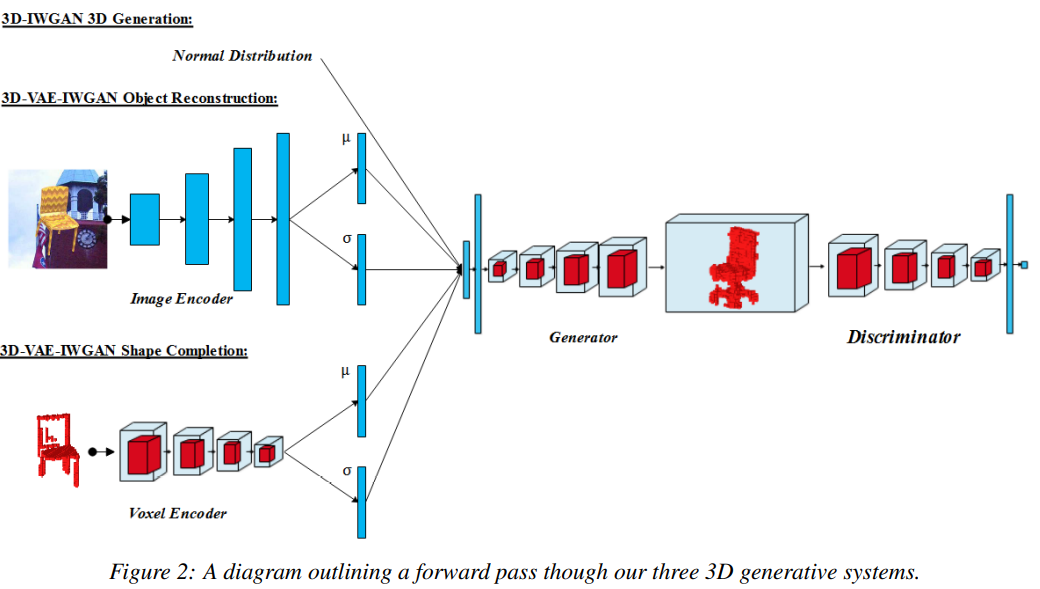
- 整体算法上来说,基本照搬WGAN-GP,额外的地方有:Generator 和 Discriminator 不是1:1迭代训练,而是 Discriminator 是Generator的5倍。Discriminator去掉了BN。但并没有Ablation Study证明有效性。

- 一共训练了456K iteration.
2022-04-14 15:46:03
217
0
0
 wuvin
wuvin