2022-07-11 15:23:01
606
0
0
Point-NeRF: Point-based Neural Radiance Fields (CVPR 2022 Oral)
- 竟然拿了 Oral,那么之前提的凭借版改进优先级又高了一些。
NeRF in the Dark: High Dynamic Range View Synthesis from
2022-05-19 10:34:39
54
0
0
The relativistic discriminator: a key element missing from standard GAN
- 不再判断一个样本的绝对真假性,而是判断相对真假性。
- 经过一系列论证和推到,操作非常简单,也就是过sigmoid转概率前相减。
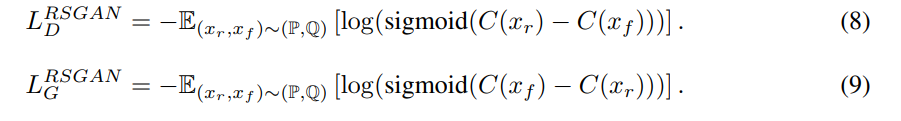
- 文章后面的实验也证实了这个简单的修改效果确实好
- 但是在github issue 中有人发现这样修改后,容易出现 model collaspe.
2022-05-02 16:07:11
86
0
0
Which Training Methods for GANs do actually Converge?
- 一篇理论性的文章,结果没有多么惊艳。但今后写某些文章的时候可能可以用于作为理论依据。

Optimizing the Latent Space of Generat
2022-04-28 16:23:12
83
0
0
- 本次以点云和体素生成为主,目的是调研下到底多大的算力能支持多复杂的场景。
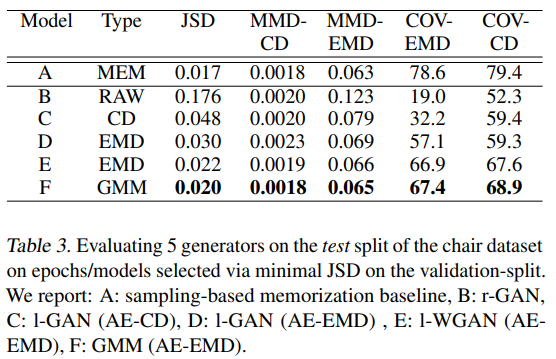
Learning Representations and Generative Models for 3D Point Clouds (2018)
- 重建部分为 AutoEncoder,生成部分结构为常见GAN或者在AE的hidden space 上做GAN or 高斯混合模型。输入输出维度为 2048*3。GAN的深度只有一两层MLP。使用的数据集大小大约为 1.4GB,57K 个样本,代码中GAN的训练使用了268K iteration。
- 重建质量

- 不同方法的结果(竖着的是不同的测评方法;B是直接GAN;CD是在AE的hidden space 做GAN,AE使用了不同的损失函数Earth Mover's Distance 和Chamfer Distance;E是WGAN;F是Gaussian Mixture Model):
Improved Adversarial Systems for 3D Object Generation and Reconstruction (2018)
- 算法结构:
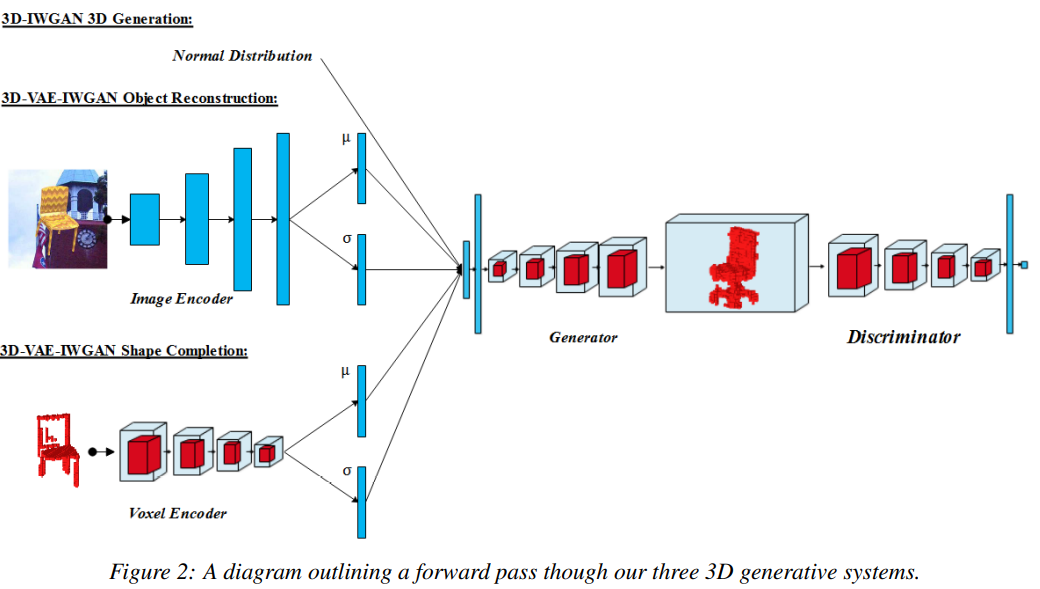
- 整体算法上来说,基本照搬WGAN-GP,额外的地方有:Generator 和 Discriminator 不是1:1迭代训练,而是 Discriminator 是Generator的5倍。Discriminator去掉了BN。但并没有Ablation Study证明有效性。

- 一共训练了456K iteration.
2022-04-14 15:46:03
127
0
0
2022-03-18 18:06:46
99
0
0
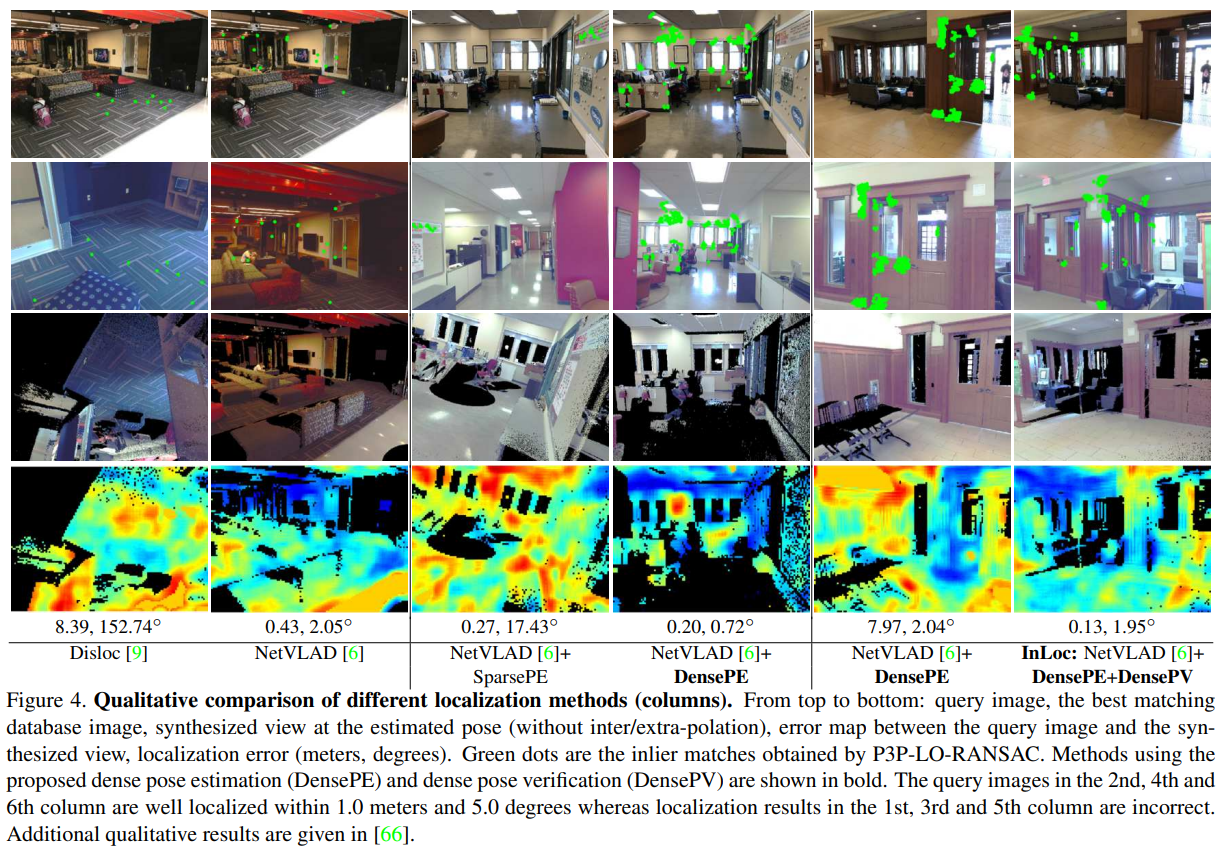
InLoc: Indoor Visual Localization with Dense Matching and View Synthesis (2018)
- 本文提出了一个先针对建筑建立3D地图,随后使用相机估计当前位姿的方案.
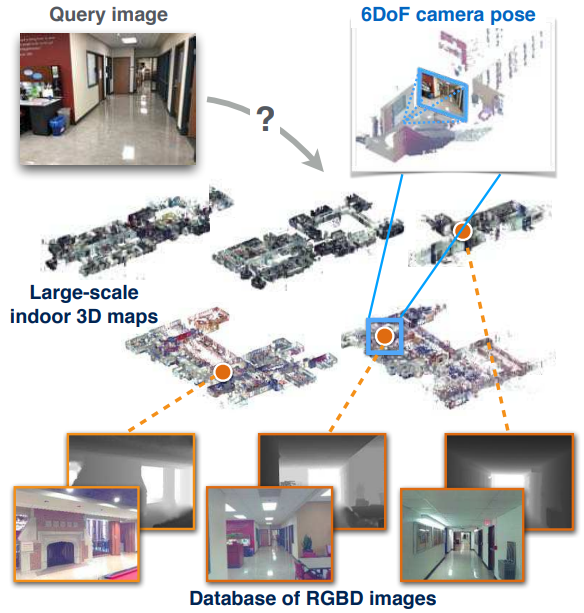
- 本文的创新点:
- 之前的方案无法在室内场景中提取足够的特征(如墙面)。本文采用 multi-scale dense CNN features (CNN提前预训练好,提取多层网络特征。) 用于图片描述和特征匹配。
- 本文通过将问询图像(query image)与一个通过3D模型合成的虚拟视角比较,来验证新视角是否解析正确。
- 具体流程: NetVLAD方法(一个使用 CNN 和聚类来进行图像检索的方法)查询图片和数据库图片,选取最高的100个,使用 multi-scale dense CNN features 来对这100进行重新排序,选出top 10 来通过合成视野进行验证。
Unifying deep local and global features for image search (2020)
- 提出了一个模型同时完成全局特征和局部特征的提取。
- 全局特征即把整张图用一个向量表示,局部特征则是提取纹理特征。
- 基于分类方法训练的模型得到的一般都是全局特征,而之前提取局部特征则是使用模型的某一层特征图通过处理得到。
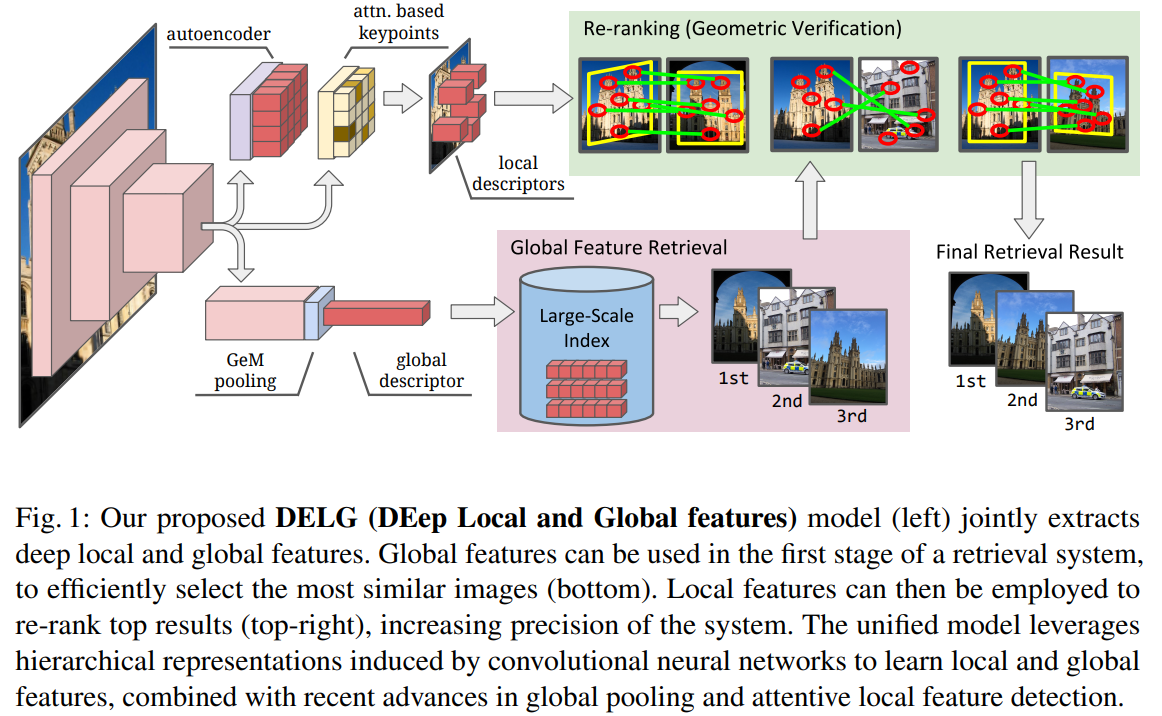
- 全局head使用了 GemPooling(即每个数的p次方和再开p次根,p可学习,本文p固定为3) 而非 AdaptiveP
2022-03-17 15:24:19
82
0
0
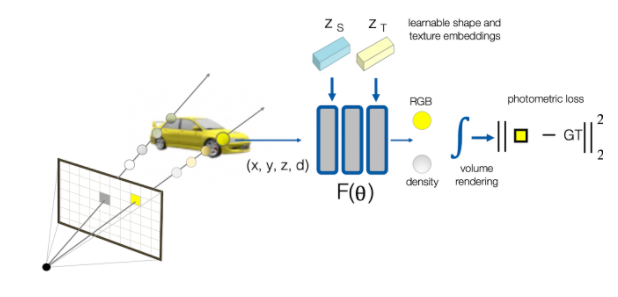
CodeNeRF : Disentangled Neural Radiance Fields for Object Categories
- 与上一个类似,把shape和color分离,但是是在MLP层实现。同样 Zs和Zt是和网络在一起优化的。

StyleNeRF: A Style-based 3D-Aware Generator for High-resolution Image Synthesis
2022-03-10 16:37:40
607
0
0
- 大尺寸城市NeRF,做到了不同尺度的nerf的统一。
- 可以考虑作为我们工作的数据集,但是还没有公开代码和数据集。
Main Idea
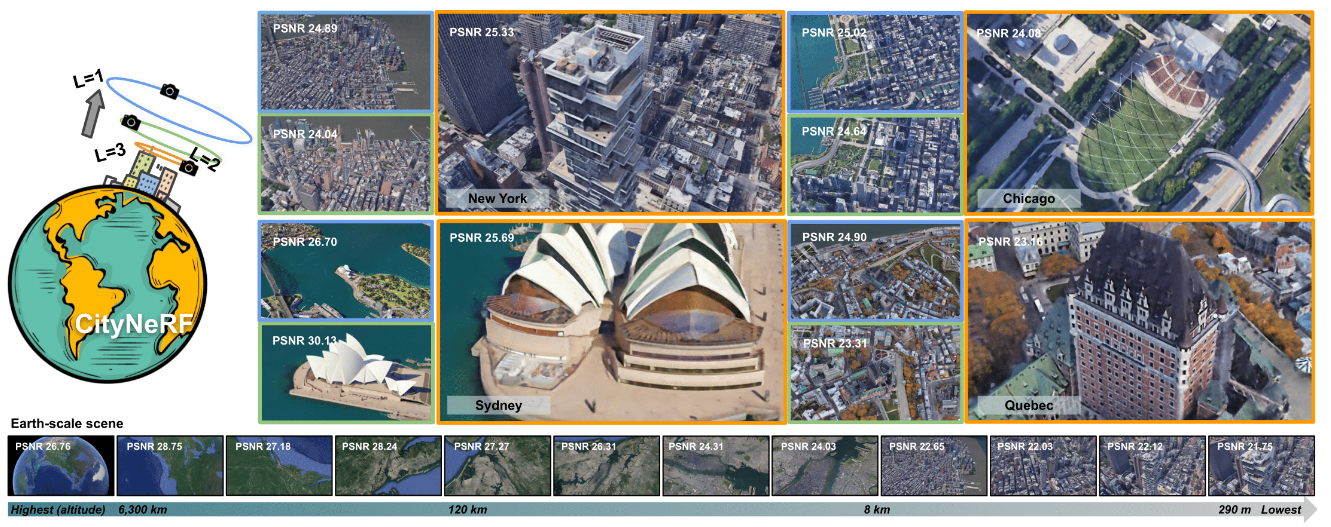
- 同样采用progressive 的训练方式,逐渐训练更大尺寸的NeRF。每个尺度的结果等于这个尺度加上之前的结果,算是一种相对新的大尺寸nerf思路。
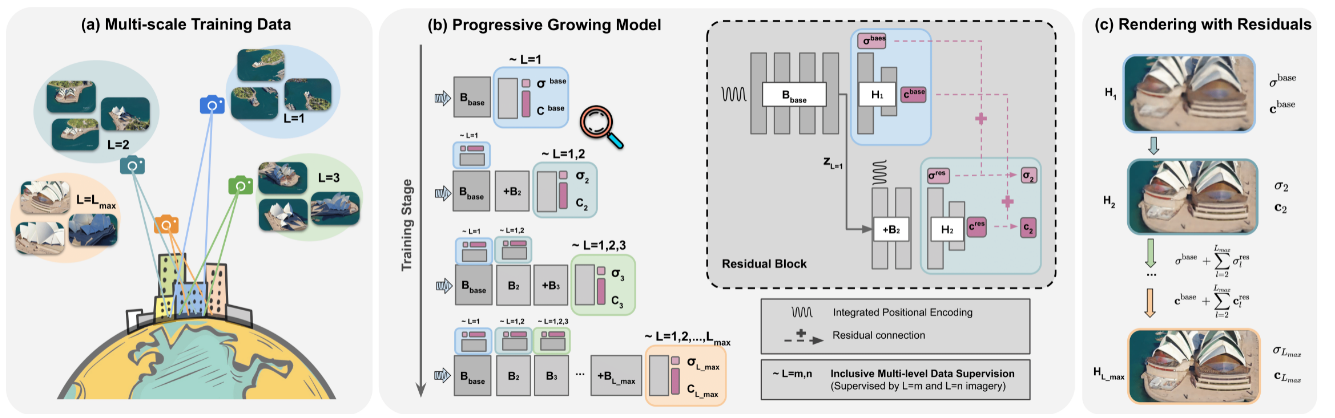
- 近距离场景PSNR也差不多只有 21~22,说明我们 rural 场景重建也差不多这么多。可能与场景比较复杂,航拍精度有限有关。
- 以及这个结构估计训练和inference 都非常耗时,但是这个结构应该可以与地图加载相结合进行动态的模块加载。
2022-03-03 10:17:05
318
0
0

- 结合了点云和nerf,就像我们是约等于 Voxel+NeRF 一样,这个方案生成的是离散的特征点。而之前所有基于网格的训练方案得到的是规整的网格点。
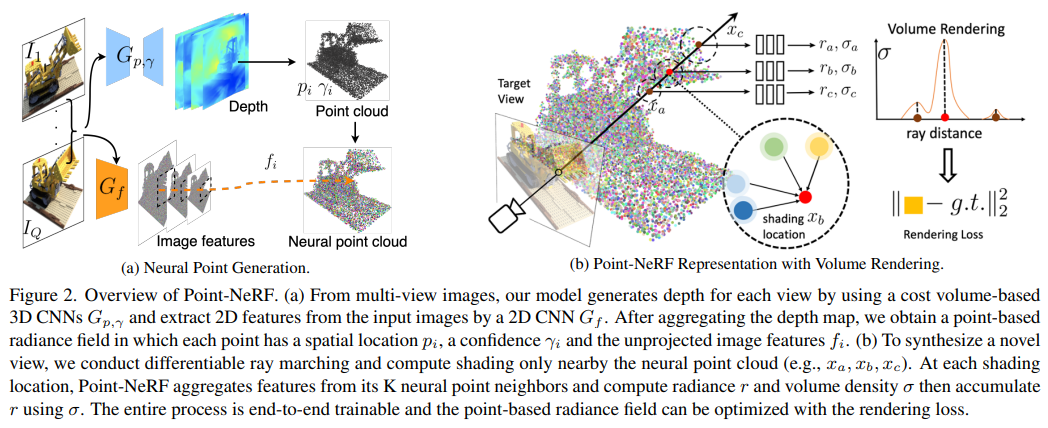
- 但是就训练速度而言,比 NeRF 快,比基于网格的一系列方法慢。
- 作用上除了加速训练,作者还提出了 point pruning 和 growing 的迭代操作,即不停的在表面处空隙添加point,并删除认为在空的地方的point。这个后处理操作可以增加渲染得到的准确度,以及可以对于一个点云输入jing'x
2022-01-13 16:41:19
111
0
0
Learning a Probabilistic Latent Space of Object Shapes via 3D Generative-Adversarial Modeling

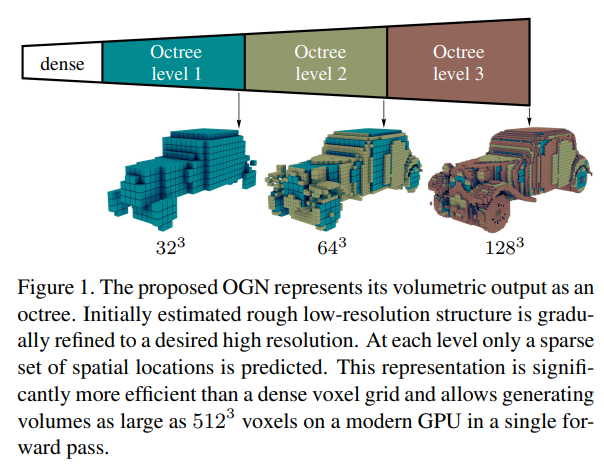
Octree Generating Networks: Efficient Convolutional Architectures for High-resolution 3D Outputs

Visual Object Networks: Image Generation with Disentangled 3D Representation

Improved Adversarial Systems for 3D Object Generation and Reconstruction

Learning Representations and Generative Models for 3D Point Clouds


PointFlow: 3D Point Cloud Generation with Continuous Normalizing Flows


Shape Inpainting using 3D Generative Adversarial Network and Recurrent Convolutional Networks


Learning Efficient Point Cloud Generation for Dense 3D Object Reconstruction


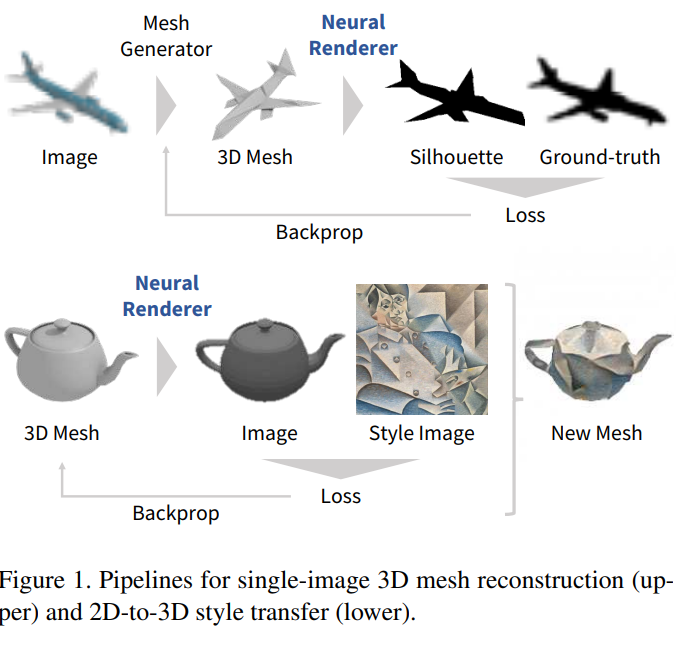
Neural 3D Mesh Renderer

SurfNet: Generating 3D shape surfaces using deep residual networks



BSP-Net: Generating Compact M
 wuvin
wuvin