Rockdu's Blog
“Where there is will, there is a way”
亲 您的浏览器不支持html5的audio标签
Toggle navigation
Rockdu's Blog
主页
数据结构
字符串算法
图论
数论、数学
动态规划
基础算法
[其它内容]
计算几何
科研笔记
归档
标签
多模态Transformer
? 论文笔记 ?
2023-07-21 11:10:54
268
0
1
rockdu
? 论文笔记 ?
.md source [Multimodal Transformers.md](http://leanote.com/api/file/getAttach?fileId=64b9fa74ab6441793681964f) ## 1 Transformers基础 ### 1.1 原始的transformer模型 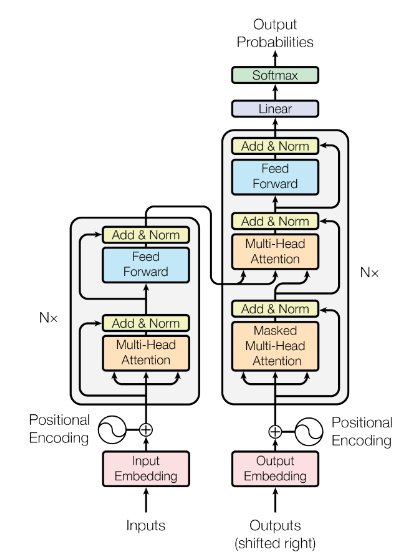 **Attention** $$ \text{Attention}(Q, K, V)=\text{Softmax}(\frac{QK^T}{\sqrt d}) V $$ 其中$Q$是$n\times d$矩阵,$n$表示询问的条数;$K$是$m\times d$矩阵,$m$表示待被查询的点数,每个key向量维度为$d$;$V$是$m\times d_v$矩阵,$m$表示待被查询的点数,每个value向量维度为$d_v$ Softmax是对每一行做Softmax **Attention**输出为$n\times d_v$矩阵 **Multihead Attention** $$ Q=\text{concat}(q_1, q_2, ..., q_c)\\ K=\text{concat}(k_1, k_2, ..., k_c)\\ V=\text{concat}(v_1, v_2, ..., v_c) $$ 其中$q_i$为$n\times \frac d c$矩阵,$k_i$为$m\times \frac d c$矩阵,$v_i$为$m\times \frac {d_v} c$矩阵 $$ \text{MHA}(Q, K, V) = \text{concat}(\text{Attention}(q_1, k_1, v_1), ..., \text{Attention}(q_c, k_c, v_c)) $$ **MHA**输出依然为$n\times d_v$矩阵,一般$c$可以取8 **Self Attention** Self Attention即为$Q,K,V$都由同一个向量序列经过线性层生成的Attention,即 $$ \text{SA}(X)=\text{Attention}(XW_Q, XW_K, XW_V) $$ Multihead Self Attention同理 $$ \text{MHSA}(X)=\text{MHA}(XW_Q, XW_K, XW_V) $$ 由于为Self Attention,$n=m$成立,因此$QK^T$的大小为$n\times n$ **Masked Multihead Self Attention** 将每个decoder块中的**第一个**Multihead Attention层(即不引入encoder信息的那一个)中的所有Attention换为Masked Attention 这是由于在真正推理时,decoder的self attention中每一个点的查询只能查到自己位置之前的点,而在训练时如果将一个序列一起通过decoder两两之间都是可见的。因此,需要引入一个mask矩阵$M$,来对每个点蒙上位于它之后的所有点 $$ \text{MaskedAttention}(Q, K, V)=\text{Softmax}(\frac{QK^T}{\sqrt d} \odot M) V $$ $$ M=\begin{pmatrix} 1 & -\infty & \cdots & -\infty \\ 1 & 1 & \cdots & -\infty \\ \vdots & & \ddots & \vdots \\ 1 & 1 & \cdots & 1 \end{pmatrix} $$ 其中$M$为一个$n\times n$矩阵,与$QK^T$大小相同;其左下三角部分包括对角线为1,右上三角部分全为负无穷。由于$M$为$QK^T$的第$i$行第$j$列元素乘上一个系数,而$QK^T$该位置的元素表示$j$点的value向量在$i$点查询中的贡献系数,因此将$M$的右上三角部分赋值为负无穷就可以保证在做softmax时所有点的查询查不到位于其后的点 **FFN (Feed Forward Network)** 就是含有一个隐藏层的全连接 $$ \text{FFN}(X)=\sigma(XW_1+b_1)W_2+b_2 $$ 其中$X$是一个$N\times d_v$矩阵,$\sigma$激活函数常见的有$\text{ReLU}(\cdot),\text{GELU}(\cdot)$等 ### 1.2 Post-LN & Pre-LN 如何选择 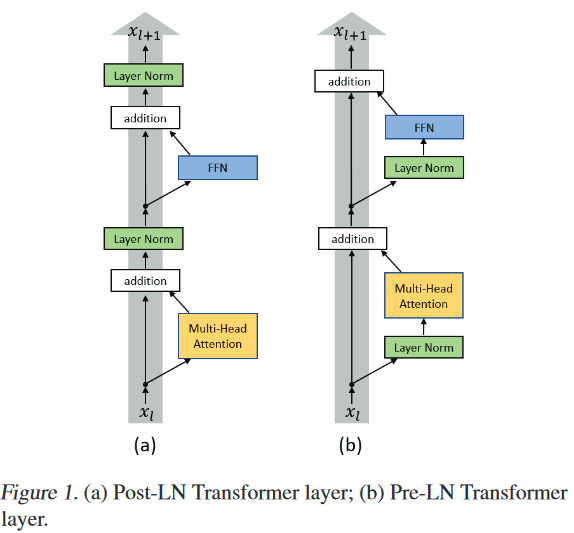 - pre-LN更容易训练(可无需warmup,收敛快),post-LN性能潜力更大 - 一种理解:pre-LN类似于隐式增加模型的宽度而缩减了模型的深度 - On Layer Normalization in the Transformer Architecture:可能是因为pre-LN的梯度模长稳定且较小 - Understanding the Difficulty of Training Transformers:扩大效应 ### 1.3 Vision Transformer (ViT) 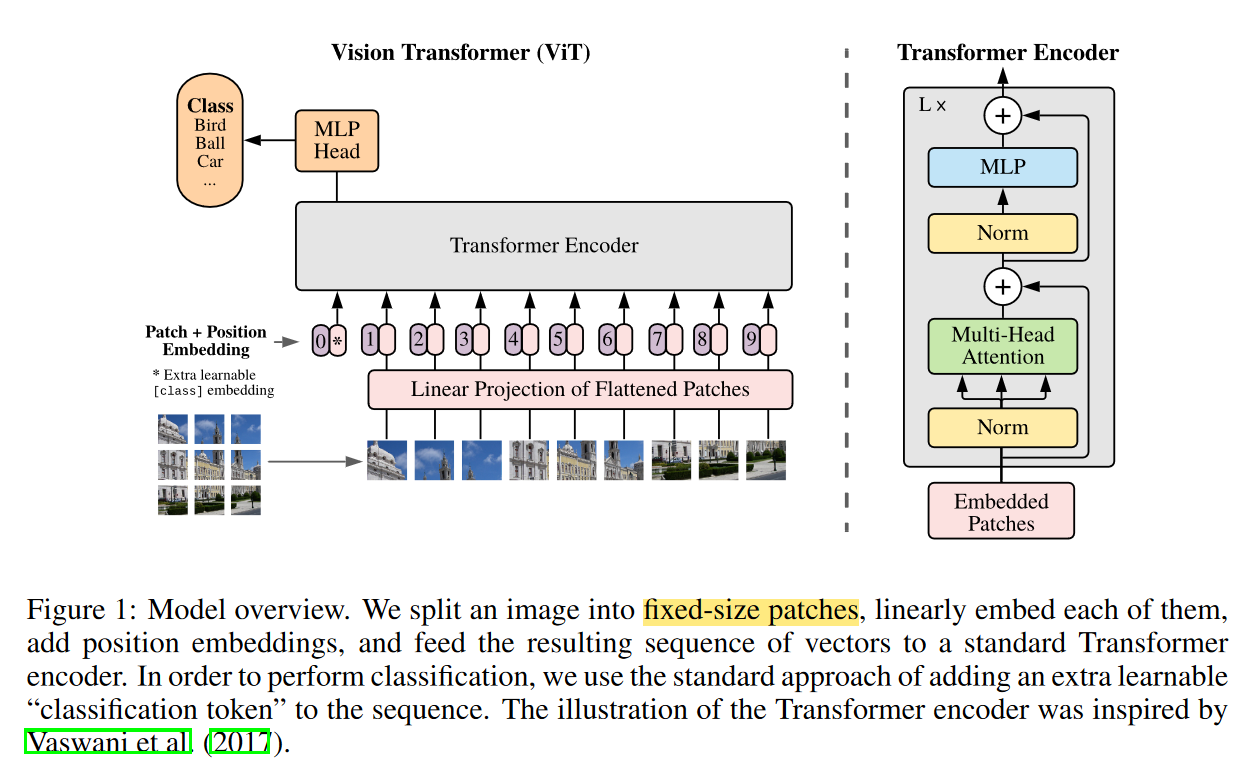 - An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale - 图片划分为许多patch,从左到右从上到下拉成一维,通过线性层变换为token - 此时,原图就相当于$HW/P^2$长的“一句话”,其中$P$是patch的大小为$P\times P$ - 在0位置添加一个特殊token——[class]表示该位置用于汇集分类信息,输出时0位置的向量接MLP分类头 ### 1.4 BERT 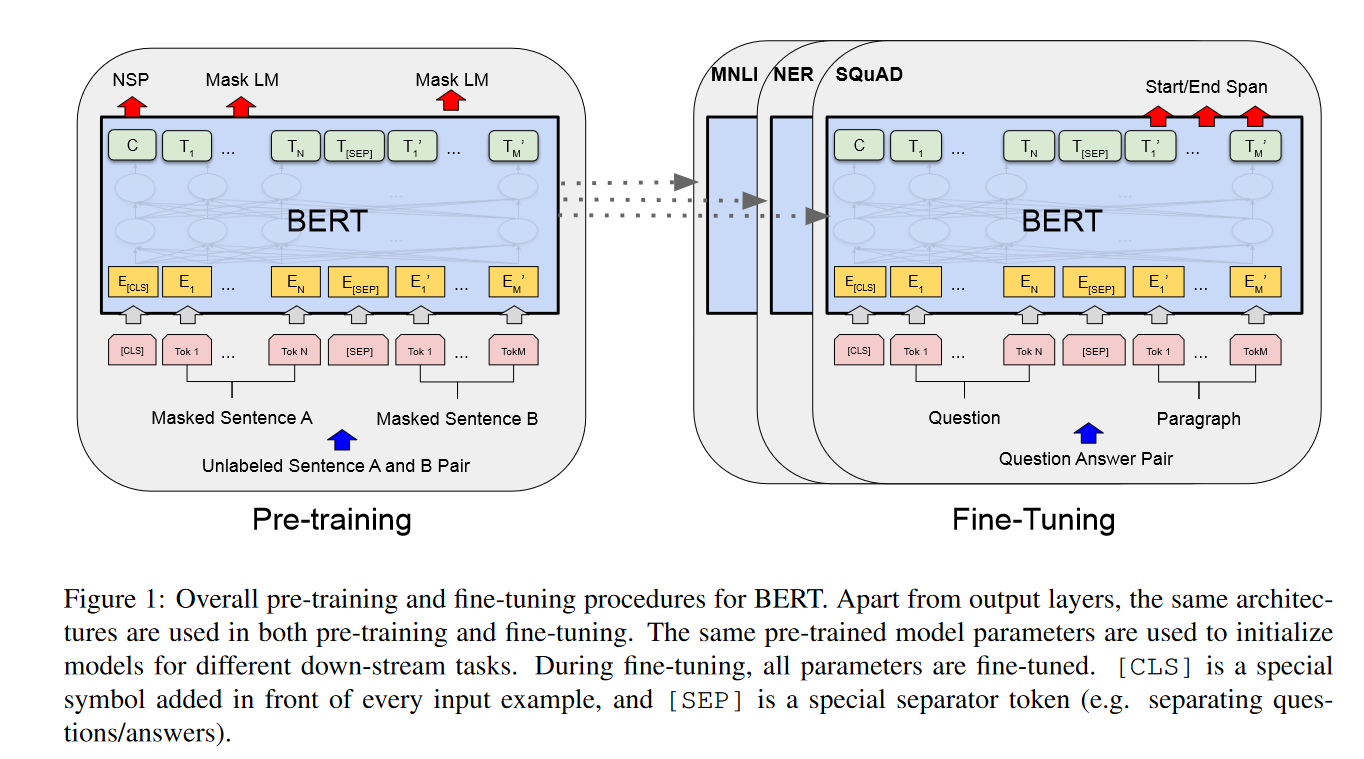 - 模型预训练:在pretext tasks训练大模型 - 训练一般的DL模型,任务目标有分类、语义分割、目标检测等 - 预训练也是一种训练,用于预训练大模型的任务目标有Masked Language Modelling,Masked Image Modelling等 - 在pretext tasks上训练大模型,训练好的大模型尽可能识别了数据集的各种特征,能很好地应用到下游任务中 - BERT的两个pretext tasks: - Masked Language Modelling:将句子中的词随机替换为特殊token [Mask],训练模型通过残缺的句子预测原来的句子(通俗版:就是完形填空) - Next Sentence Prediction:一个分类任务。输入模型的sequence有两句话A和B,且开头为特殊token [CLS]表示这个位置的输出向量将接MLP分类头完成分类任务——判断B是否为A的下一句。 ## 2 Tokenization & Embeddings of Modalities 个人理解,任何的对token进行特征提取或空间映射的方法都可以作为embedding方法 ### 2.1 Image **Patch** 把图像分成许许多多小块,每个小块直接把$P^2\cdot C$个像素值拉通为一个一维向量,通过一个**全连接层**映射到$D$维,其中$P$是patch的边长,$C$是通道数对于RGB为3,$D$是transformer内部向量的维数即隐空间维度 - ViT **RoI** 使用目标检测模型输出的框作为图片的token,通入**CNN**获得embedding - ViLBERT ### 2.2 Text **Word** 字/词,对每个字词学习获得embedding矩阵(word2vec) - 可以使用预训练的embedding - 也有使用图网络提取特征做embedding的:每个字词为节点,上下文关系为边,使用图网络提特征做embedding ### 2.3 Video **Clip of sampled frames** 视频的采样帧划分为片段(clips),每个片段使用(预训练好的)**3D CNN**提取特征,每个片段为一个token - VideoBERT 也可以用Patch作为token,全连接层做embedding ### *2.4 EHRs (Electronic Health Records) **Code** EHR为许多条目的时序序列,每个条目中有一些规范化编码的术语如诊断ICD、过程CPT、实验室指标LOINC、药物开具RxNorm,许多工作以这些代码为token - G-BERT:ICD+CPT,本文认为同一个病人同一时间的的诊断和过程描述顺序无关,因此可以不加入PI(位置编码信息) - Med-BERT:ALL,本文加入了位置编码,但是顺序并非语序而是重要程度顺序(如主要诊断、次要诊断、……) ### 2.5 Embedding Fusion: 实例 一般表现为把同一个token位置上不同种类信息的embedding直接相加 例1:BERT的三种embedding 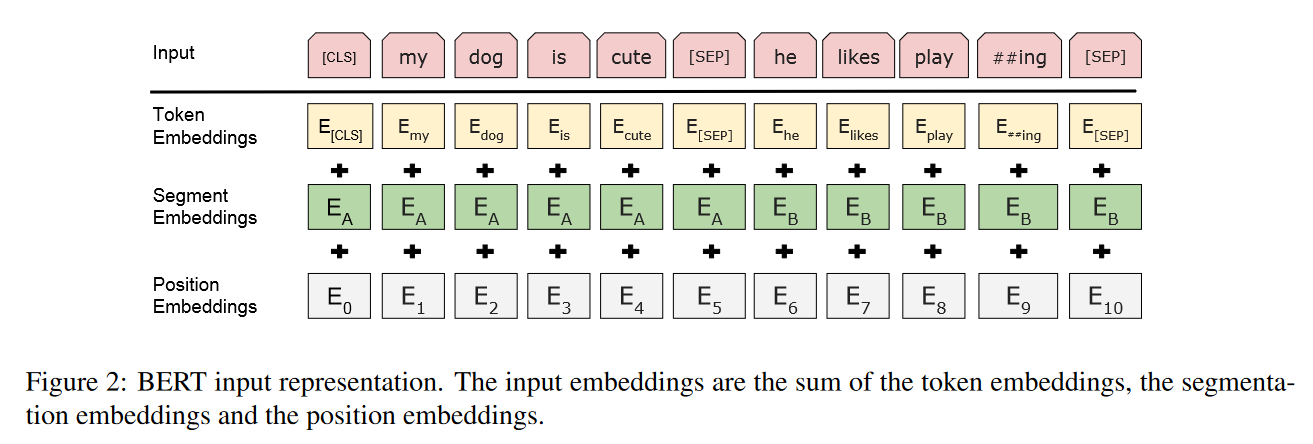 - 除了经典的token embedding和position embedding以外还新增了segment embedding来表示A,B两句话 例2:VL-BERT ICLR2020的四种embedding 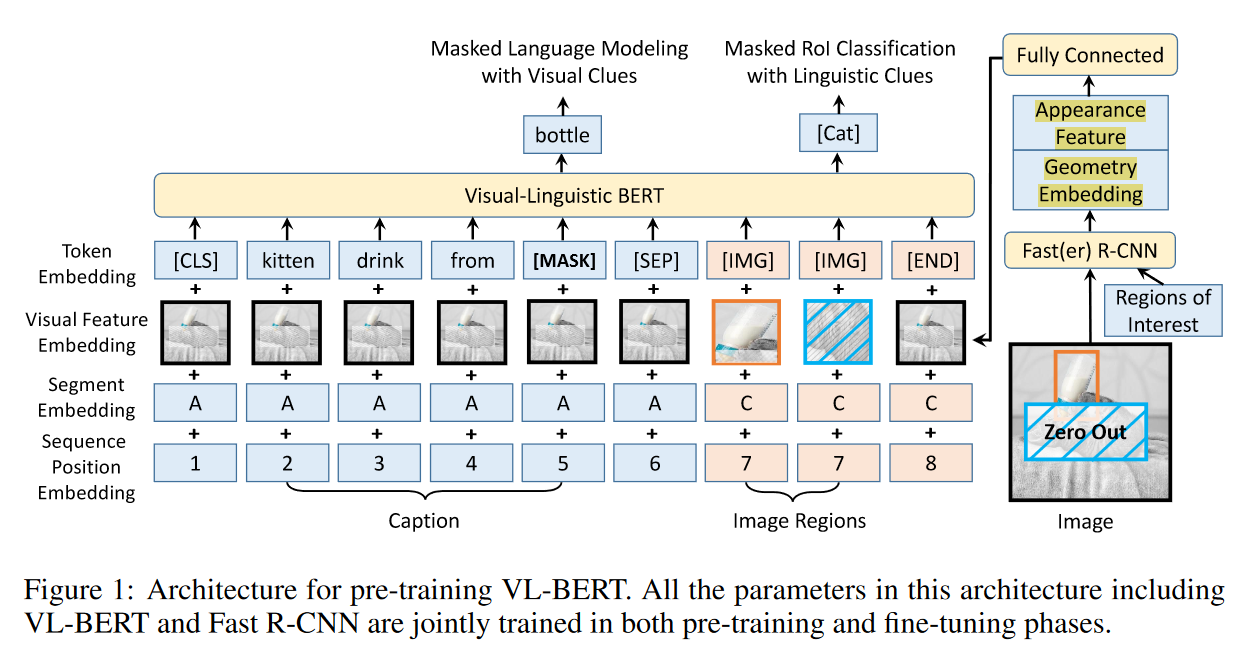 - **token embedding**:狭义token的embedding,指文本的词和special token,其中[IMG]作为一个special token出现 - **segment embedding**:标记段类型:A/B/C三种类,A表示文本段上文(BERT的上下文判断任务中的上文),B表示文本段下文,C表示图像段下文,本文的segment embedding是可学习的 - **sequence position embedding**:标记位置,对于每个token标注其位置顺序即可;注意图像段中所有token的sequence position相同,因为RoI理论上来说是没有顺序的。本文的位置embedding也是可学习的 ## 3 Multimodal Self Attention Variant  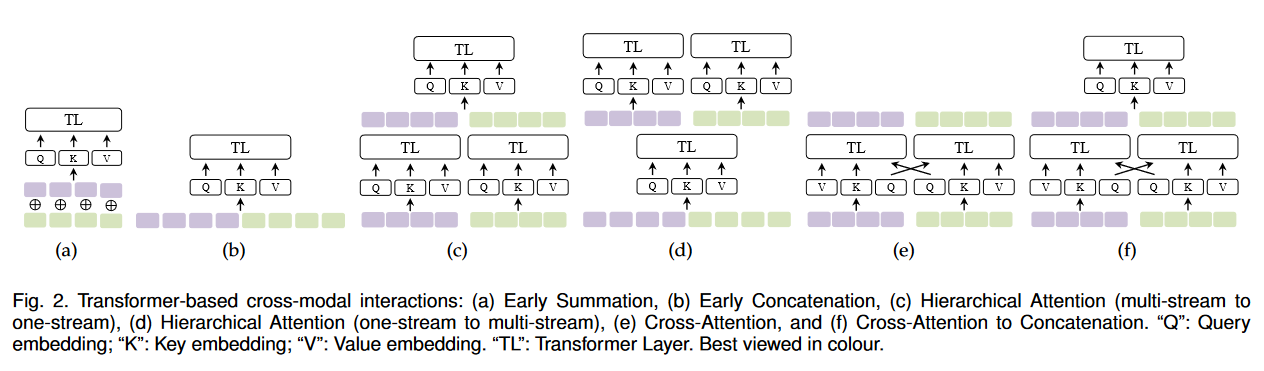 - 符号: - $Tf$:transformer模块 - $\mathcal C$:concat链接 - **Early Summation**:将不同模块的信息token-wise相加,最简单的方式 - **Early Concat**:比较常见的方式,将不同模态的信息直接concat起来 - 缺点:transformer的输入序列长度增加导致计算开销增大 - **Hierarchical Attention 1-to-2**:不同模态输入单独通过相应的transformer,每个模态transformer的输出concat起来再通入一个大transformer - **Hierarchical Attention 2-to-1**:不同模态输入concat过后通入一个transformer,然后对输出进行concat的反向拆分,拆回两个模态输出 - 相比起多模态的fusion,这个方法只是多模态的interaction - **Cross Attention**:交换两个模态transformer的$K,V$(或交换两个模态transformer的$Q$) - **Cross Attention to Concat**:两个模态的transformer进行cross attention,将结果concat起来送到一个大transformer - 利用该交互方式的相关文章:A transformer-based representation-learning model with unified processing of multimodal input for clinical diagnostics Nature Biomedical Engineering - **Combination of the Aforementioned Methods**:上述方法可以任意组合,例如在embedding时就预先将不同模态的embedding融合,然后通入cross attention,最后concat之后进入大transformer - 大于两种模态的融合: - TriBERT NeurIPS2021 - Tribert: Human-centric audiovisual representation learning - 三模态交互被设计为将两个模块的Q向量concat为一个$Q$向量,查询剩下那个模块的$K$和$V$ ## 4 Architecture Taxonomy - 根据采用的自注意力结构可以分为:single-stream/multi-stream/hybrid-stream - 根据模态交互的时机可以分为:early interaction/late interaction(e.g. hierarchical 2-to-1)/throughout interaction(e.g. cross attention) - 多模态的早融合,晚融合,中融合 - ViLT:根据图像模态部分、文本模态部分和融合模态部分的大小关系分类 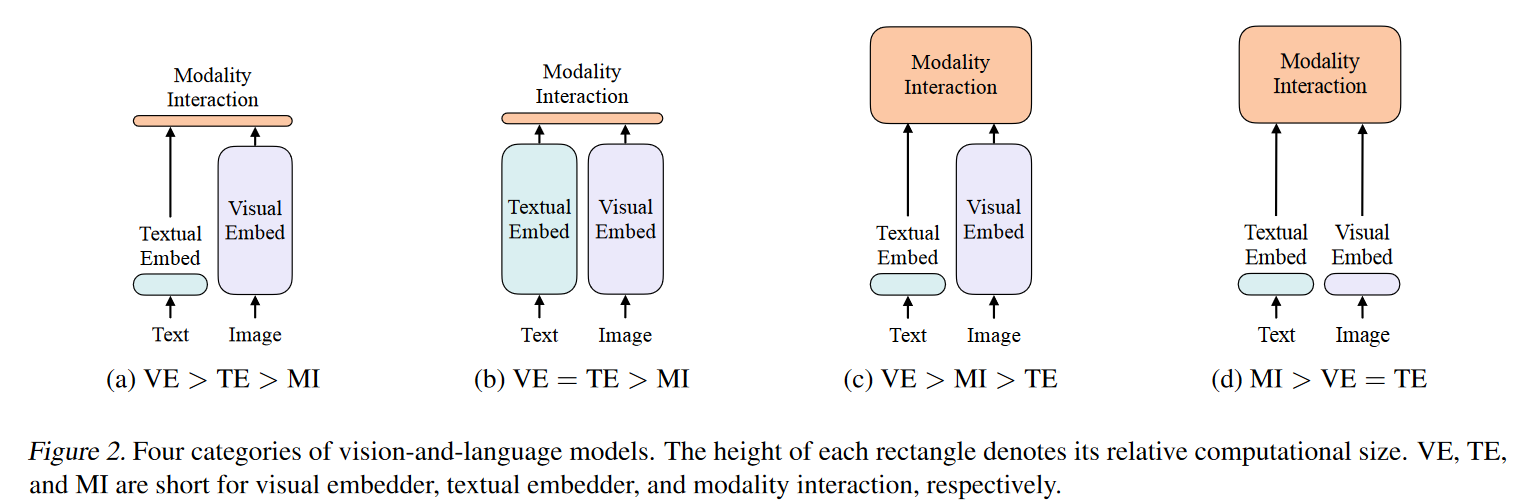 ## 5 Multimodal Pretraining ### 5.1 Task-Agnostic pretraining 三个要素:tokenization、transformer representation、objective supervision 研究趋势: - **Vision-Language Pretraining**(VLP)是一个主要研究方向:包括video-language和image-language - 当前的多模态transformer过于依赖优质的**well-aligned**数据 - 引出新问题:如何利用**weakly-aligned**甚至**unaligned**数据? - **Speech**可以用做**text**:语音转文字已经十分成熟 - 这意味着有声视频可以成为绝佳的**well-aligned**多模态语料库:VideoBERT就用到了这一点 - **pretext tasks**有极高的扩展性:一个模态的pretext task很容易扩展到另一个模态,如masked language modelling衍生出的masked image modelling和masked acoustic modelling;又如sentence ordering modelling衍生出的(video)frame ordering modelling pretext tasks分类: - 监督的(Image-Text Matching)和无监督/自监督的(Masked Language Modelling) - 目前主流为自监督pretext tasks - 根据任务目的分类:masking、describing、matching、ordering 现有的pretext tasks: 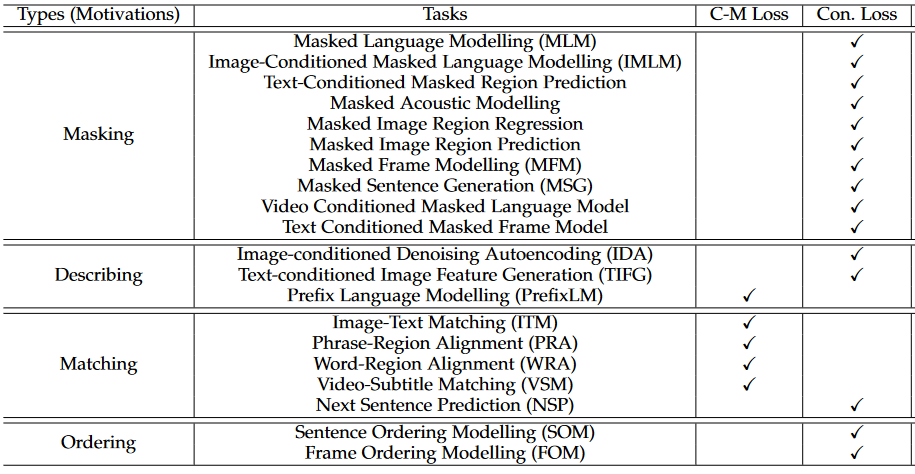 - **Ordering**:乱序重排,可以把排序看做对每个元素的分类问题,类别为顺序序号1~n - HERO EMNLP2020——FOM Frame Ordering Modelling - 随机打乱15%的帧,然后预测它们原来的顺序 问题: - 现有预训练模型比较难以直接运用于生成任务,如VideoBERT如果完成image captioning的任务必须要再额外训练一个decoder才可以。因此,如何得到既可以完成**生成任务**又可以完成**判别任务**的预训练模型是一个问题 - 提升多模态预训练性能的一些探索: - 多任务学习: - 问题:复合任务预训练的多种loss应该如何平衡、pretext tasks复杂程度和难度对模型的影响不确定 - 相关文章:Multi-task Learning of Hierarchical Vision-Language Representation - 对抗学习 ### 5.2 Task-Specific Pretraining 为什么能做任务无关预训练还要研究任务相关预训练? - 受技术限制,很难找到广泛适用所有任务的一套网络结构、pretext tasks和语料库数据 - 客观来讲,不同下游任务之间存在不能忽视的差别 因此,许多下游任务需要精心设计预训练过程 ## 6 Challenges ### 6.1 Fusion 分类: - Early/Middle/Late Fusion: - 不同工作主要区别在于混合的模态种类不同和masking的方法不同 #### Tricks - Bottleneck Multimodal Fusion NeurIPS2021 - 提升模型性能 - ?可以降低计算复杂度  ### 6.2 Cross-Modal Alignment - 常见做法:采用对比学习将不同模态的数据对映射到空间同一位置 - 代表工作:CLIP - 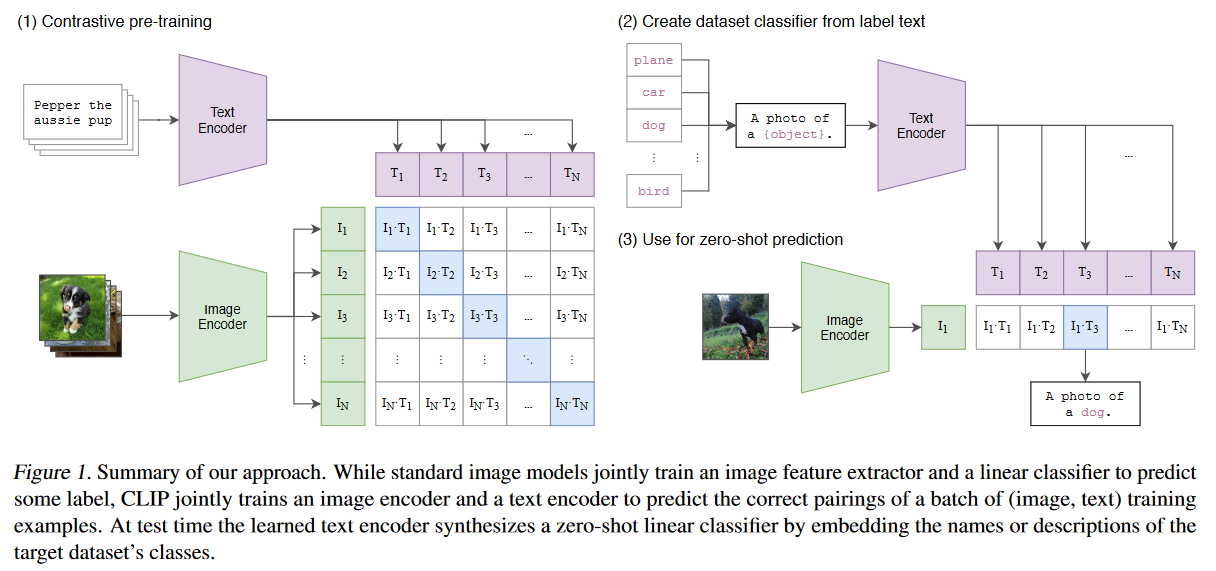 - **重要启发**:原始的图像分类任务被看做是单模态任务,难以做到zero-shot;然而利用多模态图像文本对齐进行分类给出了解决方案——在对齐模型上用prompt engineering方法可以做到zero-shot分类 - 将目标图片和n个A photo of {label}送入CLIP,其中{label}替换成不同的要分的类别,CLIP一个概率最高的出来 ### 6.3 Efficiency - 主要效率问题:Transformer的Self Attention随序列长度二次增加复杂度为$O(N^2d)$,其中$N$为序列长度,$d$为维数 解决方案: - **知识蒸馏**:把大transformer蒸到小transformer - 简化模型: - **ViLT**——极简的VLP模型:ICML2021 - 极简化模态各自的编码过程,对图像模态也只像文本一样做个patch embedding,一进来就开始模态融合 - 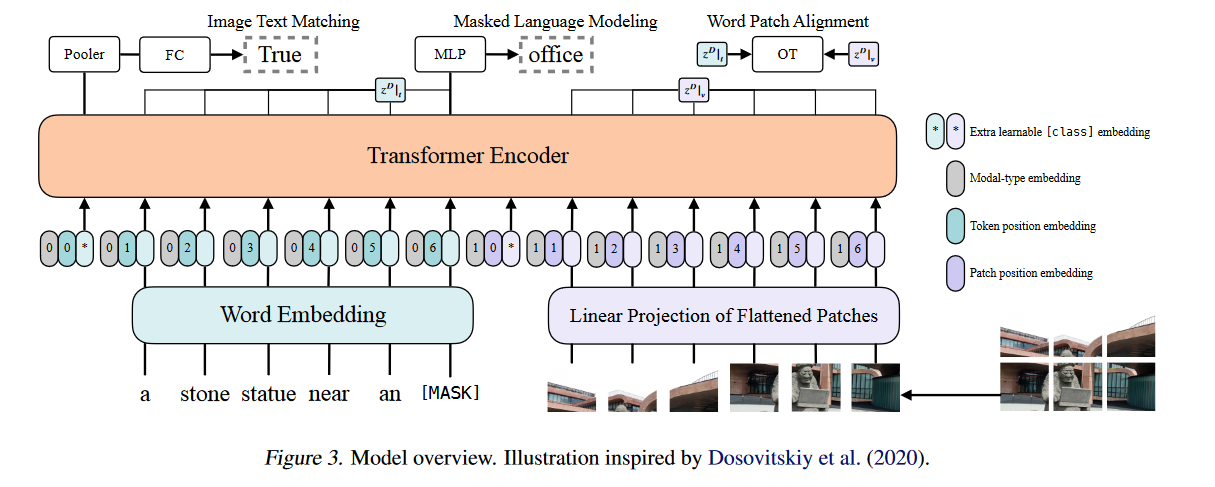 - 附:Visual embedding的各种策略 - 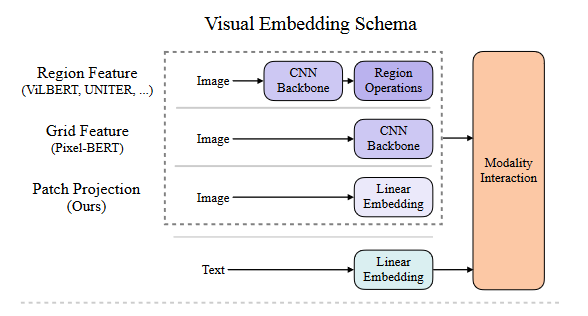 - **DropToken**?感觉没用 - VATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text NeurIPS2021 - 虽然提升了效率,但会降低性能,实际上拿小规模数据训练低性能网络,可能有细微泛化性提升 - **Parameter Sharing** 靠谱 - Parameter Efficient Multimodal Transformers for Video Representation Learning ICLR2021 - 基于分解的参数共享 - 提高训练数据利用率 - 模态内自监督 - 多种形式的模态间监督 - 相似数据对之间的最近邻监督 - **模型压缩与剪枝** - 寻找多模态Transformers的最优子结构和子网络 - 对transformer的模型剪枝 - 训练时冻结部分层 - 优化复杂度瓶颈——Self Attention层的$O(N^2)$ - 如RWKV - 优化多模态交互部分
上一篇:
快速排序与快速选择
下一篇:
MRI影响缺失模态分割论文&总结[更新中]
0
赞
268 人读过
新浪微博
微信
腾讯微博
QQ空间
人人网
提交评论
立即登录
, 发表评论.
没有帐号?
立即注册
1
条评论
More...
文档导航

 Rockdu's Blog
Rockdu's Blog

没有帐号? 立即注册